Devlog | 이밸 토큰으로 탐색 깊이를 동적으로 조절하기 (V4)
이전 체스 엔진인 V3는 상황에 따라 깊이를 확장하는 기능을 추가했었다. 탐색 깊이는 기본적으로 4로 고정이되 체크를 두는 수가 나오면 깊이를 1만큼 확장하여, 체크가 아닌 수를 4번 두거나 깊이가 10이 될 때까지 계속 탐색을 깊게 진행하는 방식을 사용하였다. 그런데 깊이 4로만 해도 꽤 오랜 시간이 걸렸고, 3|2 형식의 경기에서는 시간 초과로 패배하는 경우가 제법 있었다. 이번 엔진은 시간도 염두에 두면서 체크와 같은 중요한 수에 더 많은 탐색 깊이를 투자할 수 있는 조금 다른 접근법을 사용하려고 한다. 교과서에 있는지 없는지는 정확히 모르겠지만 아무튼 내가 고안한 방법이다보니 수학적으로는 논리가 명확하지 않을 수 있지만, 최소한 나한테는 논리적이었다.

이전 체스봇인 V2는 탐색할 수의 정렬로 알파베타 탐색의 효율성을 극대화할 수 있었지만, 여전히 깊이를 ...
blog.koreamobilegame.com
토큰 제한을 통한 탐색 깊이의 동적 분산
V4는 V3와 이전 모델에 비하면 획기적으로 다른 모델을 사용한다. 알파베타 탐색을 사용하는 것은 맞는데, 깊이의 제한이 없다! 말도 안 되는 이야기처럼 들리지만, V4의 알파베타 탐색은 토큰이 넉넉하게 있기만 하다면 원하는 만큼 탐색해도 관계없다. 어떤 포지션을 평가할 때마다 (이밸 함수를 호출할 때마다) 이밸 토큰을 하나 사용해야 하는데, 깊이에는 제한이 없으므로 토큰이 많기만 하다면 계속 이밸 함수를 부르며 탐색을 이어나갈 수 있다. 그럼 한 번의 수 계산에 사용할 수 있는 토큰의 총량을 제한하면 "pseudo-무제한" 깊이 탐색을 진행하면서 가장 중요하게 수 계산에 사용할 수 있는 시간을 제한할 수 있다. 수 계산에 쓸 수 있는 시간이 한정적이라면 수 계산에 사용할 수 있는 토큰의 총량을 줄이면 되고, 시간이 넉넉하다면 더 깊은 탐색을 위해 토큰을 넉넉하게 줄 수 있다.
토큰은 최대한 공평하게 분배된다. 초기 포지션에서 최선의 수를 찾는데 100개의 토큰을 받았고 5개의 적법한 수가 있었다고 하면, 처음에는 각 수에 20개의 토큰을 분배할 것으로 계획을 잡는다. 그럼 깊이 1의 포지션은 20개의 토큰을 다시 깊이 2의 포지션들에게 최대한 공평하게 분배하고, 이와 같은 과정을 반복하여 토큰이 하나밖에 남지 않는 포지션들을 만든다. 토큰이 하나인 포지션은 더 이상 토큰을 분배할 수 없으므로 그 하나의 토큰을 자기 포지션의 이밸에 사용한다. 그런데 토큰의 개수가 적법한 수의 개수의 배수가 아니라면, 어떤 수는 다른 수보다 토큰을 적게 받아야 할 것이다. 이 경우, V2에서 구현한 수 평가 휴리스틱이 높은 순서대로 토큰을 많이 받는다. 즉, 수의 퀄리티에 따라 토큰이 차등 분배된다. V2에서 이미 휴리스틱의 값이 감소하는 순서로 최대 힙에 넣었고, 알파베타 탐색의 효율을 극대화하기 위해 이미 휴리스틱이 큰 것부터 탐색하기 때문에, 단순히 탐색하는 순서대로 최대한 공평하게 토큰을 나눠주면 된다.
여기서 V3에서 구현한 체크 후 깊이 확장의 아이디어를 계승하기 위해 만약 수가 체크이면 토큰을 더 많이 받는 시스템을 구현하였다. 앞의 예시처럼 최선의 수를 찾는데 100개의 토큰을 받았고 5개의 적법한 수가 있었다고 하자. 100개의 토큰 중 20개를 수 1번에 투자하고 결과를 얻은 후, 수 2번에 토큰을 투자해야 한다. 총 80개의 토큰이 남았고 4개의 수가 남았으므로 여기에도 20개의 토큰을 투자하면 될 것 같았지만 알고보니 이 수는 체크를 놓는 수다! 그러면 체크는 두 개의 "가상 수"로 간주하고 아까의 과정을 적용하면, 총 5개의 가상 수가 있고 80개의 토큰이 남아있으므로 각 "가상 수"마다 16개의 토큰을 투자하면 된다. 그런데 이 수는 두 개의 "가상 수" 값을 가지므로 32개의 토큰을 갖게 된다. 이후 수 3~5번에 사용할 수 있는 토큰은 100-20-32 = 48이므로 나머지에 16개의 토큰을 투자할 수 있다.
이렇게 하면 체크인 수에 두 배 가량의 토큰을 투자할 수 있을 뿐만 아니라, 휴리스틱 값이 안 좋은 포지션들이 좋은 포지션에 비해서 전반적으로 낮은 토큰 개수를 받게 되어 좋은 포지션의 탐색 깊이를 전반적으로 늘리는 데에도 기여한다. 설령 체크를 두는 수가 단 한 개도 없었다고 하더라도, 시스템 상 휴리스틱 값이 낮은 수들은 높은 휴리스틱을 갖는 수보다 많은 토큰을 가져갈 수 없다. 이는 좋을 것으로 기대되는 수에 대한 탐색을 강화하고, 그다지 좋지 않을 것 같은 수들에 대해서는 탐색 깊이를 줄여 유의미한 탐색의 비중을 늘린다는 점에서, 비교적 단순한 시스템임에도 불구하고 기능적으로는 굉장히 복합적인 일을 한다.
구체적인 구현 계획
원래는 탐색을 시작하기 전에 토큰을 미리 분배해둔 "토큰 트리"를 만들고 할 계획이었는데, 시간적으로도 너무 복잡해질 것 같기도 하고, 무엇보다 체크의 유무에 따라 토큰의 개수를 차등 지급하려면 체크인지 아닌지 판별을 해야하는데, 현재로서는 직접 둬보지 않고는 체크인지 아닌지 판별할 수 없다. 이걸 미리 판별하는 방법들을 생각해보긴 했으나, 직접 둬보는 것과 큰 속도 차이가 나지 않을 것 같아서 일단 미뤄뒀다. 그것보다, 어차피 최대 힙에 따라서 휴리스틱에 따라 정렬되어 포지션이 pop된다면 그냥 "real-time"으로 토큰을 분배해도 괜찮을 것 같았다.
대략적인 아이디어는 위에서 설명했고, 여기는 조금 더 테크니컬한 부분들에 대해 설명하려고 한다. 앞서 설명한 바와 같이 알파베타 탐색 함수에는 깊이가 없지만 V3에서 구현한 "깊이에 따른 페널티"를 구현하기 위해 깊이를 인자로 받는다. 재귀함수이다 보니 서로 다른 프로세스끼리 소통하는 방법이 전역변수나 인자로 전달하는 방법 말고는 마땅히 없는데, 전역변수를 쓰기는 여러모로 부적절해서 인자로 전달한다. 여전히 알파와 베타 인자, 최소화/최대화 플레이어 여부는 하는 일도 그대로고 전달 방법도 같다. 추가로, 각 노드마다 분배해야 할 토큰의 개수를 파라미터로 전달한다. 이런 변화들을 종합하면 V4의 알파베타 메소드는 다음과 같다.
실제 수를 두는 메소드인 mkmv 함수는 단순히 알파베타 탐색 함수를 호출하고, 몇 가지 사소한 정보를 출력하는 wrapper에 불과하다.
위 코드에서 token_init은 이 경기 전체에 쓸 수 있는 토큰의 총량이고, V4 코드에 의하면 토큰 하나당 70 μs정도가 걸리는 것 같고 토큰 개수와 소요 시간에 정비례관계가 있는 것으로 확인되어서, 선형 관계와 몇 가지 실험을 이용해 3분 경기에 사용할 수 있는 토큰 개수를 계산해보니 약 200만개였다. 그래서 token_init은 전역변수로 200만으로 설정해두었고, 경기 하나가 100턴을 넘기는 경우가 거의 없어서 매 턴마다 쓸 수 있는 토큰 개수는 token_init을 100으로 나눈 값으로 설정하였다.
실제 알파베타 함수의 내부를 살펴보면, 먼저 수를 둔 후 체크인지 판별하여, 만약 체크라면 "가상 수"의 개수를 추적하는 virtual_move_count를 하나 늘려 해당 수는 가상 수 2개의 몫을 하도록 했다. 이후, 토큰을 할당하는 과정에서 기본 수에 할당할 토큰 개수는 남은 토큰의 개수 (remaining tokens) 를 남은 가상 수의 개수로 나눈 후 올림하여, 최대한 공평하지만 동률일 경우 먼저 오는 수에 더 많은 토큰을 지급하는 방식으로 코드를 구성하였다. 체크가 발생한 수일 경우 앞에서 구한 값의 두 배만큼 토큰을 지급하였다. 수를 탐색하고 나면, 그 수가 소비한 토큰의 개수만큼 남은 토큰을 줄이고, 그 수가 "몇 가상 수"인지를 가상 수의 개수로부터 빼서, 해당 과정을 반복하였다.
V4에 대한 평가
V4는 V3보다 빠르면서 V3의 성공 포인트를 최대한 계승하는 것을 목표로 하는 엔진이라, V3보다 잘 할 거라고는 예상하기 어려웠고 최소한 V2보단 잘 해야한다는 생각을 갖고 평가에 임했다. 확실히 V3보다 시원시원하게 수를 두긴 하나, 어떤 이유에서인지 V2보다 확연히 못했다. 정말, 실력차이가 확실히 나는 것이 그 빠른 경기에서도 느껴질 수준이었다. V2는 두지 않을 블런더를 매 경기마다 하고, 뭔가 지능이 퇴보한 느낌이었다. 그래서 V4가 토큰을 제대로 분배하는지, 토큰 분배 과정 이후 깊이가 어떻게 되는지 알아봤는데, 분명 매 턴마다 200만 / 100 = 2만 개의 토큰을 받는데도 불구하고 컴퓨터는 많아봐야 5천 개 수준의 토큰밖에 사용하지 않는다는 것을 확인했고, 평균 탐색 깊이도 3 정도였다. 그래서 V2와 V3가 "토큰"을 얼마나 쓰는지 측정해봤는데, 이전 버전의 엔진들은 아무리 적게 써도 2만 개 정도의 토큰을 쓰는 것을 관찰할 수 있었다.
토큰을 많이 쓸수록 많은 포지션을 점검하고 비교했다는 것이기 때문에 아무래도 더 정확한 수를 두므로 앞서 봤던 안 좋은 결과를 어느 정도는 설명할 수 있었는데, 아직 이상한 부분이 있었다. 분명 2만개의 토큰을 지급했는데, 왜 25%도 안 쓰는거지? 그래서 토큰 분배 현황을 면밀하게 점검했는데, 예상하지 못했던 부분을 깨닫게 되었다. V4의 기본 작동 메커니즘이 알파베타 탐색이고, V2에서 최대 힙 정렬로 가지치기의 빈도를 끌어올렸다 보니, 어느 노드를 탐색하는 중간에 알파베타 알고리즘이 그 간선을 잘라내면 그 수에 할당되어있던 토큰이 사용되지 않고 사라진다는 결론에 도달했다. 나중에는 이 사라질 토큰들을 다른 노드에 투자할 수 있는 체계를 마련하면 좋겠지만, 일단은 예상하지 못했던 "좋은 점"이다! 예상보다 적은 토큰을 사용해도 된다는 점은, 다르게 말하자면 더 많은 토큰을 지급해도 된다는 의미가 된다. 원래 200만개의 총 토큰 개수 제한을 두고 진행했는데, 이는 모든 토큰이 사용될 것이라는 걸 염두에 두고 잡은 값이었다. 토큰의 대부분은 버려진다고 생각하면, 토큰 개수를 2000만개까지도 늘릴 수 있는 상황이다.
그래서 총 토큰 개수 제한을 2000만으로 올렸더니, 놀라울 정도로 빠르고 정확한 결과를 보였다. 거의 깊이 4의 V3 수준의 실력을 보이는 것 같았고, 체스닷컴 상 정확도도 V3와 비슷한데, 실행 시간은 훨씬 빨랐다. V3보다 "잡다한 수"에 투자하는 시간이 적어서 이런 효과를 볼 수 있는 게 아닌가 생각된다. 한편, V3는 의도적으로 체크가 연이어지는 수순에 대해서는 깊이 10까지 탐색하기 때문에 이론적으로는 5수 체크메이트도 볼 수 있는데, V4 엔진은 V3만큼 체크에 강한 강조를 주지 않는다. 강조를 준다고 하지만, 토큰을 두 배 주는 것은 많아봐야 두 칸 더 깊이 탐색할 수 있을 정도의 토큰량이다. 현재는 체크 수에 대해 2개의 가상 수만큼의 가치를 부여하는데, 이 값을 수정하거나 더 중요한 수에 대해서는 3개, 혹은 4개의 가상 수만큼의 가치를 부여한다면 그 수들에 더 집중할 수 있을 것이다.
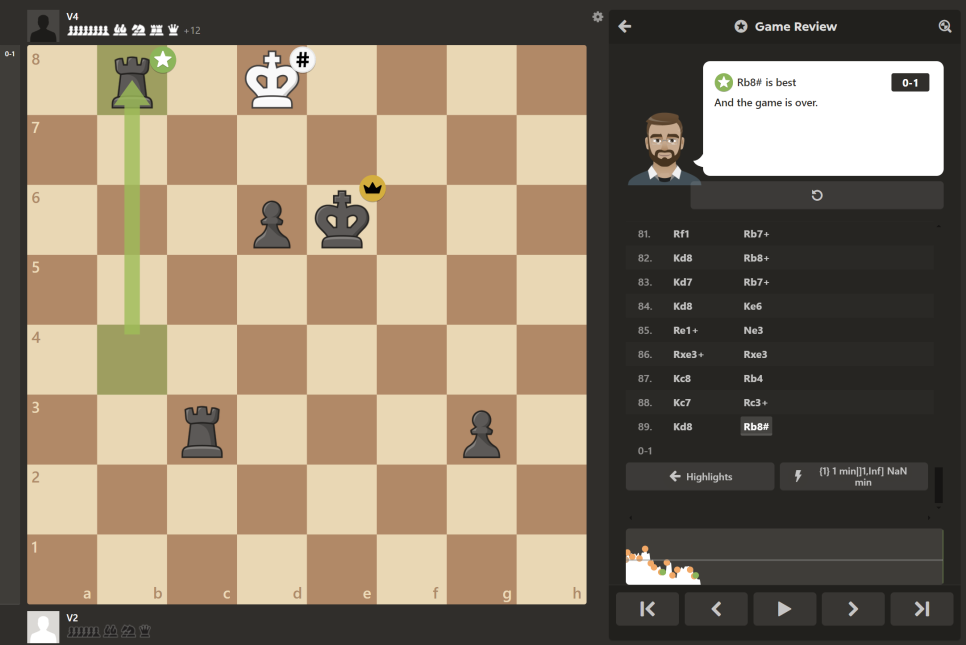
V2 vs V4: V4의 승리! (0-1)
개발자도 이번엔 처참하게 패배했다. 사실 개발자는 10분 말고는 둔 적이 거의 없어서, 이번에 봇하고 3 | 2 시간 컨트롤로 대결했는데, 정말 어따 내놓기 민망할 정도로 부끄러운 패배였다.
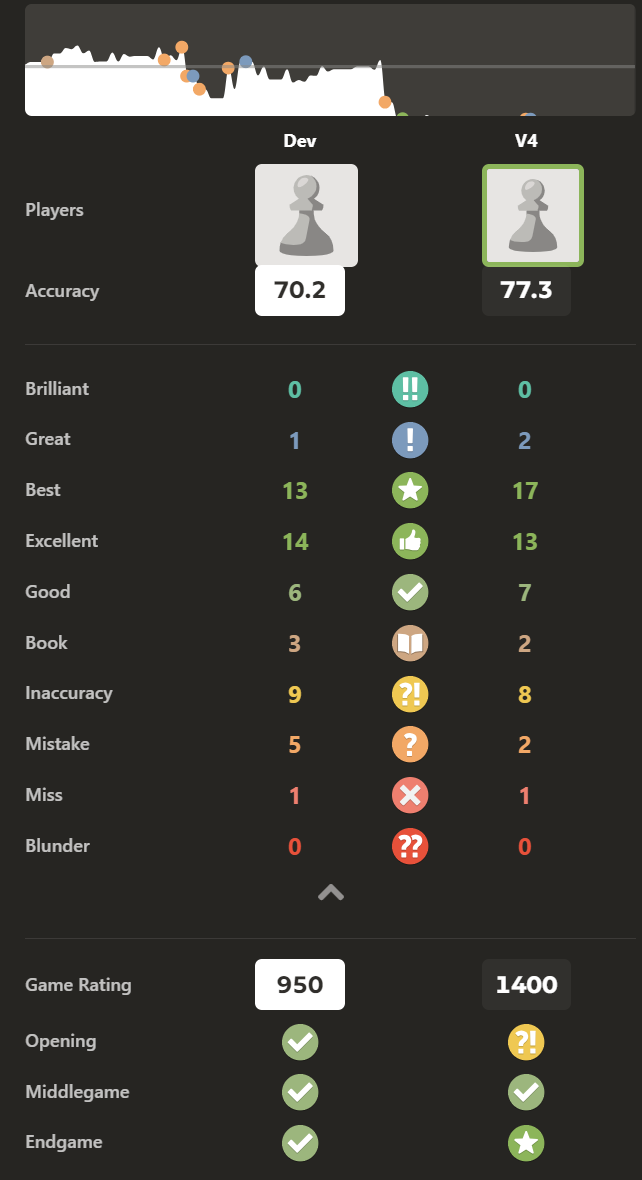
스톡피시의 이밸이 보이는가!!!!! ㅠ
V4 봇은 elo가 1400 대일 것으로 예상한다는데, 그럼 내가 지는게 이해된다! elo가 450만큼이나 차이나면, 애초에 압도당하는 게 맞다. 내가 만든 체스 엔진한테 이렇게 저항도 못하고 지는게 좀 기분은 나쁘지만, 한편으론 열심히 고민해서 만든 엔진이, 그것도 요즘 시대에 인공지능은 눈꼽만큼도 안 쓴 이 엔진이 꽤 준수한 실력을 보이는 걸 보고 뿌듯하기도 하다.
아직 V4가 한 판을 두는데 1분 이상 쓰지 않는다. 이론적으로는 토큰 개수를 6000만개, 심지어는 1억개까지로 늘려도 사실 꽤 빨리 수를 계산할 것이라는 건데, 다양한 값들을 넣어보며 실험해볼 계획이다.
개선점
늘 그렇듯, 개선할 여지도 많아 보인다. 앞서 언급한 것과 같이, 버려지는 토큰을 주워 다른 수를 계산하는 데 쓸 수 있으면 지금보다 총 토큰 수를 계산하기 훨씬 수월할 것 같으나, 생각보다 당장 쉬워보이진 않는다. 그냥 개발자가 멍청한 걸수도
V2나 V3 엔진의 경우 휴리스틱이 그렇게 중요한 요소는 아니었다. 물론 휴리스틱에 따라 정렬한 결과 훨씬 빠른 판단을 할 수 있었지만, 같은 깊이라면 V1이나 V2 모두 결국에는 같은 판단을 내렸을 것이다. 휴리스틱이 달라진다고 해도 결국 모든 수를 탐색하고, 그 결과에 따라 판단을 내리기 때문이다. 하지만 이 V4 시스템에서는 정확한 휴리스틱이 매우 중요하다. 예를 들어, 5개의 토큰을 받았는데 적법한 수가 10개라면, 가장 휴리스틱 값이 높은 5개의 포지션에 대해 이밸을 진행하고, 나머지 포지션에 대해서는 이밸을 진행할 수 없다. 그렇기에, 휴리스틱이 주어진 상황에서 최선의 수를 가능한 한 정확하게 집어낼 수 있어야 이밸되지 않고 버려지는 불상사를 막을 수 있다. 휴리스틱이 개선되면 알파베타 자체의 효율도 증가할테니 일석이조 아닌가!
그리고 가장 결정적으로, 각 토큰마다 소요되는 시간을 줄이면 더 많은 토큰을 쓸 수 있을테니, 이밸 함수를 최적화하는 과정이 필요할 것이다. 물론 코드 자체의 비효율도 있겠지만, 아직 알고리즘적으로 개선할 여지가 많이 있는 것 같아, 이밸 함수 최적화와 개선이 한동안 목표가 될 것 같다. 특히, 이런 유형의 게임에서 자주 쓰이는 방법 중 하나인 transposition table을 구현하지 않았는데, tttable이 캐시의 역할을 하면서 이밸을 더 빠르게 진행하고 더 복잡한 이밸을 수행할 때 부담이 덜할 것이다. 아무래도 V5의 주제가 될 것 같군! V5에서는 transposition table을 구현하고, 이밸 함수가 현재로선 잡지 못하는 미묘한 부분들을 잡는 것을 목표로 할 것이다.